
[Examplary web page contextualization for enhanced decision making of LLM agent.]
[Examplary web page contextualization for enhanced decision making of LLM agent.]
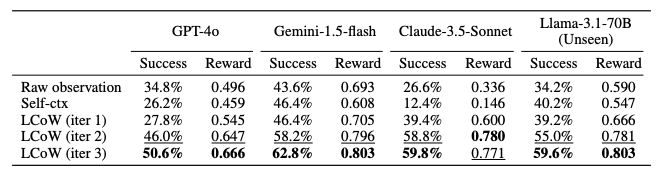
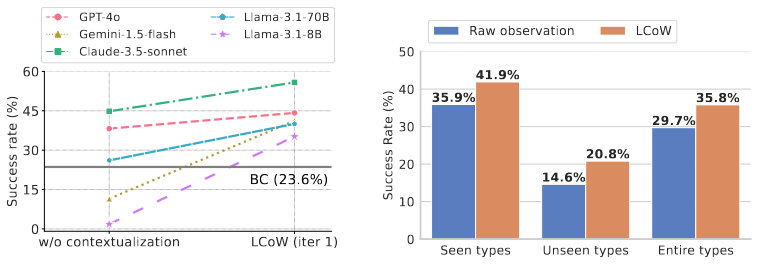
Recent advances in large language models (LLMs) have led to a growing interest in developing LLM-based agents for automating web tasks. However, these agents often struggle with even simple tasks on real-world websites due to their limited capability to understand and process complex web page structures. In this work, we introduce LCoW, a framework for Learning language models to Contextualize complex Web pages into a more comprehensible form, thereby enhancing decision making by LLM agents. LCoW decouples web page understanding from decision making by training a separate contextualization module to transform complex web pages into comprehensible format, which are then utilized by the decision-making agent. We demonstrate that our contextualization module effectively integrates with LLM agents of various scales to significantly enhance their decision-making capabilities in web automation tasks. Notably, LCoW improves the success rates of closed-source LLMs (e.g., Gemini-1.5-flash, GPT-4o, Claude-3.5-Sonnet) by an average of 15.6%, and demonstrates a 23.7% average improvement in success rates for open-source LMs (e.g., Llama-3.1-8B, Llama-3.1-70B) on the WorkArena benchmark. Moreover, the Gemini-1.5-flash agent with LCoW achieves state-of-the-art results on the WebShop benchmark, outperforming human.

@article{lee2025learning,
title={Learning to contextualize web pages for enhanced decision making by LLM agents},
author={Lee, Dongjun and Lee, Juyong and Kim, Kyuyoung and Tack, Jihoon and Shin, Jinwoo and Teh, Yee Whye and Lee, Kimin},
journal={arXiv preprint arXiv:2503.10689},
year={2025}
}